Advanced Search & Replace with Regular Expressions
You know this situation: You've written a text — and now you're searching for that phrase again. Or this one term. We all know this situation — we're searching for something, but while we have an idea of what it is, we don't know exactly what to look for. The problems could begin with spelling ("recognise" or "recognize"?), extend to synonyms ("grow" or "evolve"?) up to things like "I'm searching for the only number in this text that has 6 digits". All of these are pretty common problems that we can easily solve as humans: We look for patterns.
There are certainly different approaches to the problem of complex searching, but they all boil down to us being able to recognise patterns. If we are searching for a phrase where we don't know whether we used the British English spelling or the American English one, we simply look for the words — our mind will automatically look out for these s/z-exchanges, "ou"s versus "u"s, etc. Sometimes, we even use a photographic memory. If we are certain that what we search for was written on the lower third of an odd page in a book, we'll only look at the bottom part of the book, leaving out the even pages completely.
But there are two problems to this. First, we can't apply a photographic memory to one long scrollable article on the web with no distinct pages, and second: why do the tedious job of searching digital texts manually, when we could simply automate that? This is where today's topic comes into play: regular expressions! We'll first introduce the problem that made them necessary in software, and afterwards we'll describe how you can use them with Zettlr to quickly find patterns in your texts!
Identifying the Problem
With their rather generic name (this was a pun on several levels, just continue reading!), regular expressions don't sound like one of the most powerful tools of modern computing, but believe me: they are. When computers became more capable and text files where invented, programmers faced a new kind of problem: when a program had to read in a text file and parse some input (which could range from simple configuration parameters to full texts), the normal approach to simply take one character after another and look for certain characters that would then trigger specific behaviour in the program quickly became cumbersome.
Let's take an example to make clear the extent of the problem. Let's take the INI-file format that is commonly used to set parameters for programs. INI is short for initialisation, so it contains parameters to start a program:
; These values are used to connect to the database
[Database]
name=/path/to/my/database
; The user account credentials
[Account]
name=helloworld
password=Another Password
; Collect plugins here
[Plugins]
plugin1=/path/to/some/extension/file
plugin2=/another/plugin
Parsing this file as a human being is pretty simple: We immediately see that there are three sections — Database, Account and Plugins — with some parameters. If we assume that this INI file is used by Zotero, we could immediately realise what each of the options does: The "name" property in the Database-section refers to the Zotero database on your computer where all your references are stored. Then we see the Account-section, which seems to refer to a Zotero user account, and a Plugin-section where some plugins are stored (BetterBibTex, for example, or Zotfile).
To read in this file for our program, we could write something as the following pseudo-code:
for each line in file do:
if line equals "": skip line
if line starts with ";": skip line
if line starts with "[":
startNewSection()
next line
key = ''
val = ''
equalEncountered = false
for each character in line do:
if character equals "=":
set equalEncountered = true
next character
if not equalEncountered: key = key + character
else: val = val + character
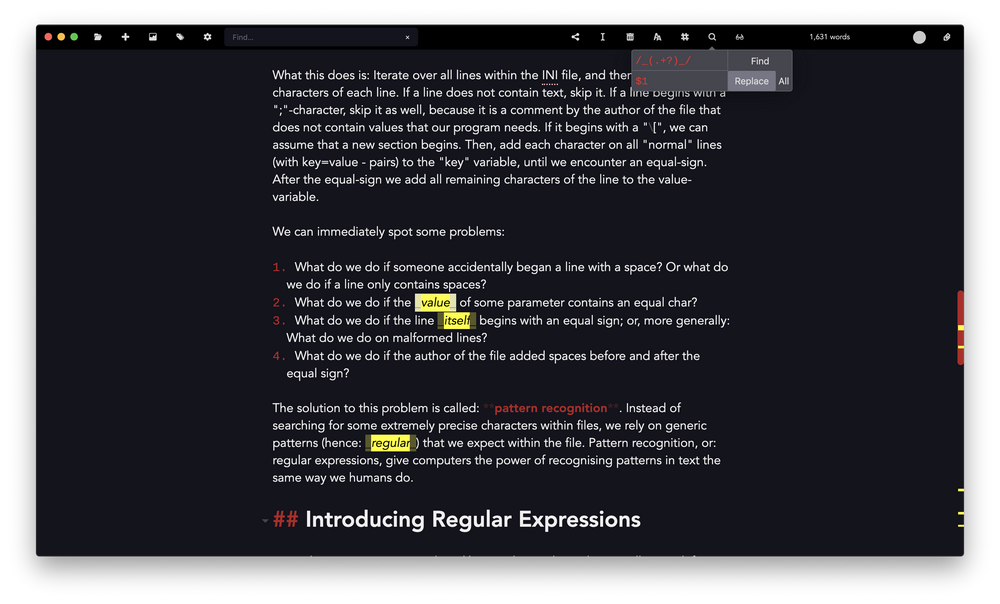
What this does is: Iterate over all lines within the INI file, and then over all characters of each line. If a line does not contain text, skip it. If a line begins with a ";"-character, skip it as well, because it is a comment by the author of the file that does not contain values that our program needs. If it begins with a "[", we can assume that a new section begins. Then, add each character on all "normal" lines (with key=value-pairs) to the "key" variable, until we encounter an equal-sign. After the equal-sign we add all remaining characters of the line to the value-variable.
We can immediately spot some problems:
- What do we do if someone accidentally began a line with a space? Or what do we do if a line only contains spaces?
- What do we do if the value of some parameter contains an equal char?
- What do we do if the line itself begins with an equal sign; or, more generally: What do we do on malformed lines?
- What do we do if the author of the file added spaces before and after the equal sign?
The solution to this problem is called: pattern recognition. Instead of searching for some extremely precise characters within files, we rely on generic patterns (hence: regular) that we expect within the file. Pattern recognition, or regular expressions, gives computers the power of finding patterns the same way we humans do.
Introducing Regular Expressions
A regular expression is something like an advanced search. Basically, you define what pattern one might expect, and then you test each line of a file against this expression. If the expression matches a line, you can then be sure that this line includes what you are looking for. Modern regular expressions even have the power to extract certain parts of such a pattern so that you don't have to manually extract all keys and values. Let's re-write our example using regular expressions this time:
keyValueExpression = /\s*(.+)=(.+)/
sectionExpression = /\[(a-zA-Z0-9+)\]/
skipLineExpression = /(^\s*;|\s+)/
for each line in file do:
if skipLineExpression matches line: next line
if sectionExpression matches line: startNewSection()
key = ''
val = ''
result = keyValueExpression.match(line)
if result is not undefined:
key = result[1]
val = result[2]
This pseudo-code is not just shorter and makes more sense to the reader, it's also much safer than the first approach. We have three expressions, one for key-value-pairs, one for section headers, and one that will match all lines that we should skip (e.g. all lines where the first non-whitespace character is a ";" and empty ones). With regular expressions we can also check if the line resembles such a pattern, and only store the results in they key- and val-variables if the expression has matched.
In this example you can already see several concepts of regular expressions. Let's break them down!
First, each regular expression is surrounded with slashes. Then you can make use of some operators. The key-value-expression, for example first matches zero or more whitespace-characters (spaces, non-breaking spaces, tabulator characters and the like) with the expression \s*. This enables us to account for accidental spaces before a key-value-pair. Next, the expression matches at least one character with the expression .+ (+ indicates "one or more" as opposed to the asterisk, which means "zero or more"). We've also surrounded the expression with braces to create a so-called capturing group. A capturing group tells the software to extract this part of the pattern for later use. We use it on the line key = result[1]. The value is captured by the second group, which is why we can easily reference it with result[2]. One can also determine exactly which characters should be contained, for instance by writing a-zA-Z0-9. The dot, on the other hand, simply matches everything.
Regular Expressions for Writing Text
Regular expressions, as we have seen, are a powerful tool to find something in texts based on patterns instead of exact matches. So if you're searching for a year, but you are not sure which one, it makes sense to only search for four-digit-numbers Unfortunately, most text editors (most notably here our arch enemy, Word) hide this powerful tool from you. Regular expressions are used by all modern editors, but normally you can't make use of them when you want to search something inside your texts. But Zettlr aims to change that. In the search popup, you can either search for exact words, or you can search using regular expressions. To tell Zettlr that you would like to search for a pattern, make sure to enclose your search in forward-slashes. Zettlr will tell you that it recognises a regular expression by switching the font in the text field to a monospaced one. If the font does not change, it means that there is an error in your expression.
To search for something, just write the regular expression as you need it, and hit return. If you would like to find all word-characters, for instance, you could use something like that:
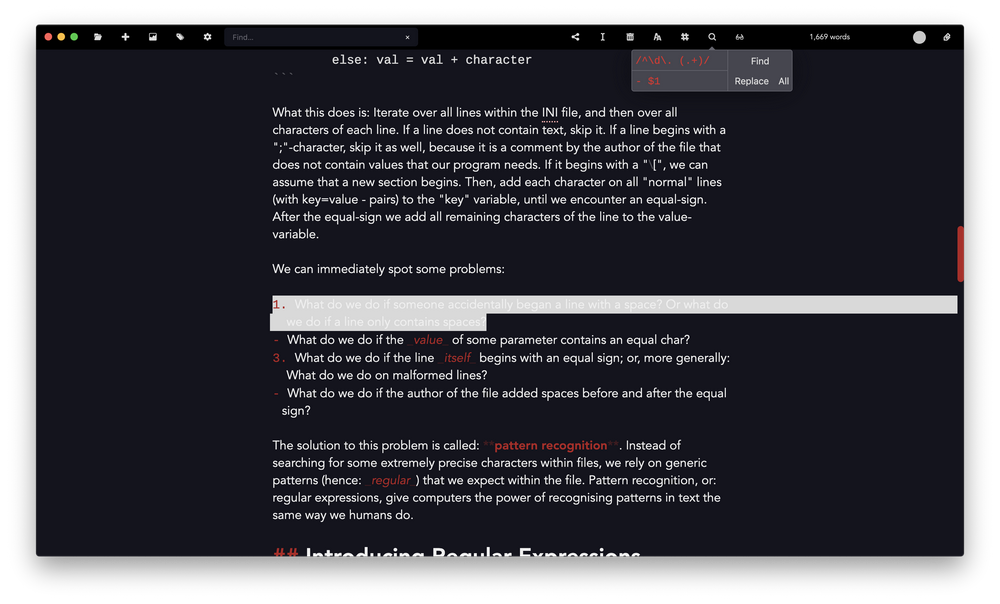
Note all the characters that the expression did not match — ampersands, braces, and hyphens, which are considered non-word-characters. Normally you don't want to simply search for words, obviously. A real-world example would be to find all emphasised text:
But what if you would like to un-emphasise the phrases? You can't simply use the replace-tool to replace them, because that would completely remove your text, does it? Well, not really. Beginning from Zettlr version 1.4 you can make use of capturing groups! So you can replace only a part of your match. To use the contents of a capturing group within your replacement text, simply refer to them using numbers. Enter a $1, to refer to the first capturing group, or $2, to refer to the second one. With this, un-emphasising your text becomes a piece of cake:
Using this approach you re-use everything in between the emphasise-characters, but leave the characters themselves out. It's easy, clean and comfortable! With this approach you could also replace the list to make it itemised rather than numbered:
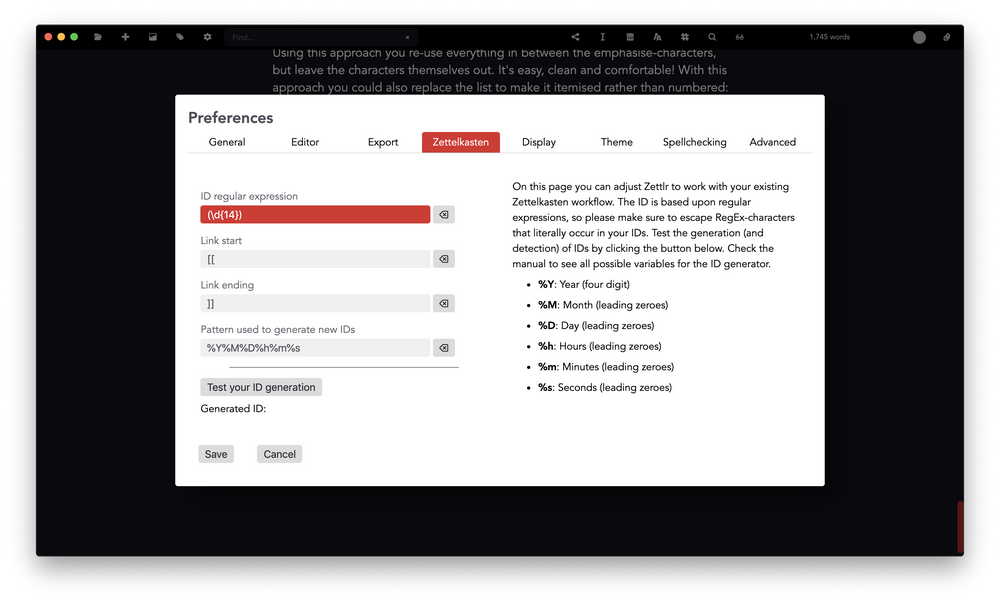
Regular expressions like these are used by Zettlr internally in a lot of places — whenever you see a clickable link, this was detected by the app using a regular expression! See an image? Also detected by a regular expression! The tags that are displayed in the tag cloud and in your file list? Also detected using regular expressions. You even have one regular expression right within your settings: the one used to find IDs!
As you can see, searching with regular expressions is really next level. But to keep regular expressions short, the inventors of regular expressions have used a lot of characters with special meaning that you have to account for. Really mastering regular expressions is an art that takes a long time to excel at. Fortunately, there are a lot of tools out there that help you do this. For instance, check out this great online tool to verify your regular expressions and have them broken up for you so that you can see what each part of your expression does! Give it a try — simply copy and paste the regular expression that Zettlr uses to detect todo lists in the tool: /^(\s*?)- \[( |x)\] /g! Add some text to see how it works! You can experiment with the settings and play around a little bit to get to know regular expressions.
Instead of playing around with regular expressions, you can also refer to this guide by Mozilla that explains regular expressions in detail and helps you understand how they work. Additionally, this guide is great because your searches are converted to RegExp-objects internally and the JavaScript-syntax for regular expressions applies. Please note that there are some subtle differences in how regular expressions react in different programming languages! Zettlr uses JavaScript regular expressions, so make sure you don't accidentally copy a regular expression intended for use with PHP or Python, as these will produce unexpected results!
Final Thoughts
Regular Expressions are a gift of modern computing and everybody should know how to utilise them to make searching more effective. They can come in handy. While one certainly doesn't need them on a daily basis, it's always good to know how to use them — because the days will most certainly come when you will need them. Familiarising yourself with such concepts is of utmost importance if you want to become a better writer. Zettlr does its best to help you write, but it's still just a tool that you need to know. It can become your Swiss knife for everything, but in order for that to happen you have to know even the "hidden" features such as regular expression searching.
We hope that with this guide to advanced searching with Zettlr helps you excel at writing!